由於此次的 Data Pipeline 有基於時間(execute_date)為條件批次執行的特性,在來源資料不確定的情況下,因此需要考慮有補檔(rerun)的可能性。所以我們必須在 Jenkins pipeline 中將時間作為一個可被注入的參數。
以下有兩種方式可以做到將時間放入 pipeline 中:
Date Parameter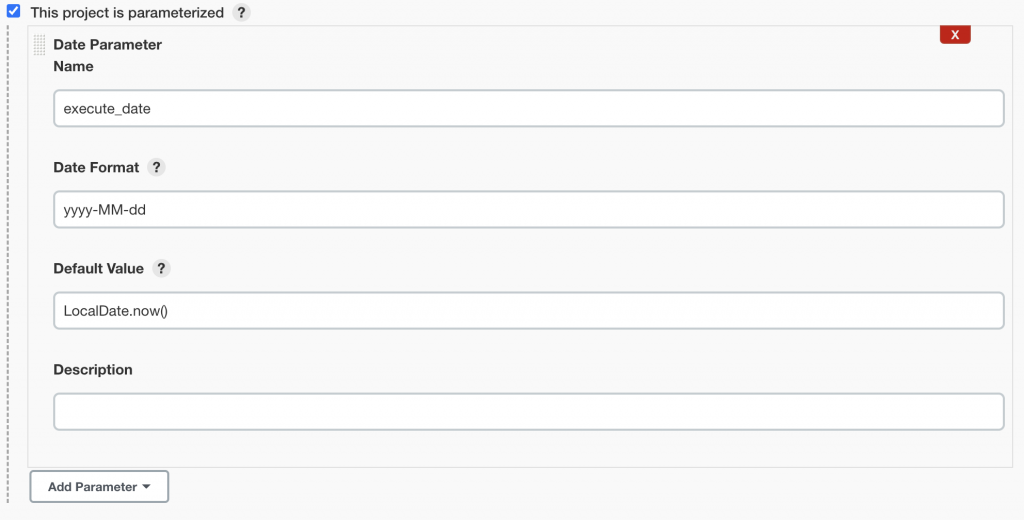

也需要安裝 Date Parameter Plugin
有位大大在 StackOverflow 給出了第一種方法的優化
properties([parameters([
[$class: 'DateParameterDefinition',
name: 'EXECUTE_DATE',
dateFormat: 'yyyy-MM-dd',
defaultValue: 'LocalDate.now()']
])])
pipeline {
...
}
在每日爬蟲資料被寫進 GCS 後,在確認資料的正確性後我們即可將單日(execute_date)的批次資料寫入 History Table
// update_content_info_hist.sql
DELETE FROM `ithome-jenkins-2022.ithome.content_info_hist_test`
WHERE DATE(crawl_datetime) = @execute_date;
INSERT INTO `ithome-jenkins-2022.ithome.content_info_hist`
SELECT
`_id`,
`crawl_datetime`,
`text`,
`user_id`,
`ironman_id`,
`title`,
`like`,
`comment`,
`view`,
`article_id`,
`article_url`,
`create_datetime`
FROM `ithome-jenkins-2022.ithome.content_info_tmp`
WHERE DATE(crawl_datetime) = @execute_date
;
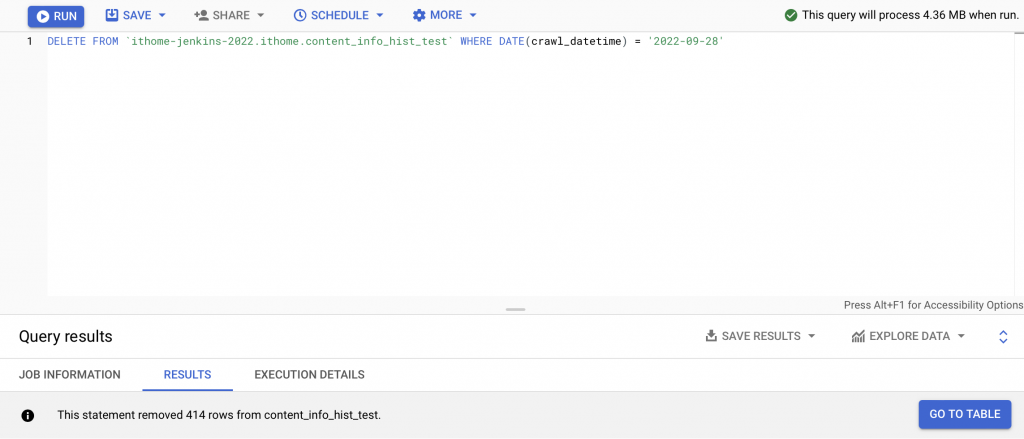
理論上應該要用 drop partition,但是 BigQuery 好像沒有直接在 SQL 下
DROP PARTITION的寫法,所以先用了一個很爛的寫法,去 full scan table 然後刪除資料 QQ 有機會再好好研究 BigQuery
BigQuery command
cat update_content_info_hist.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${EXECUTE_DATE}"
Jenkinsfile
stage("Append to history table"){
steps{
sh '''
cat sql/update_content_info_hist.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${params.EXECUTE_DATE}"
'''
}
}
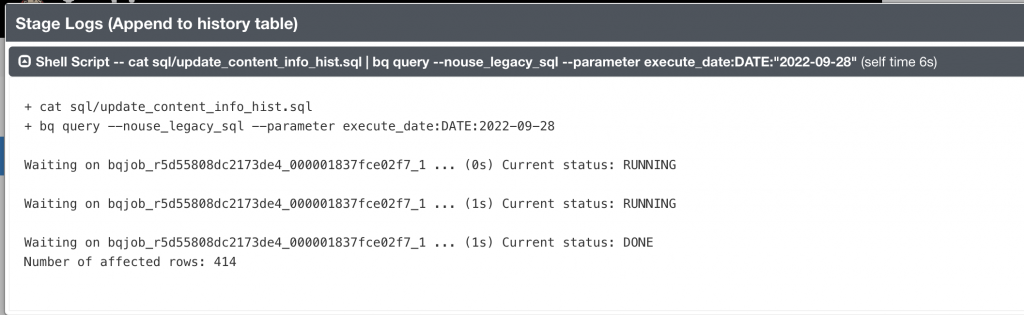
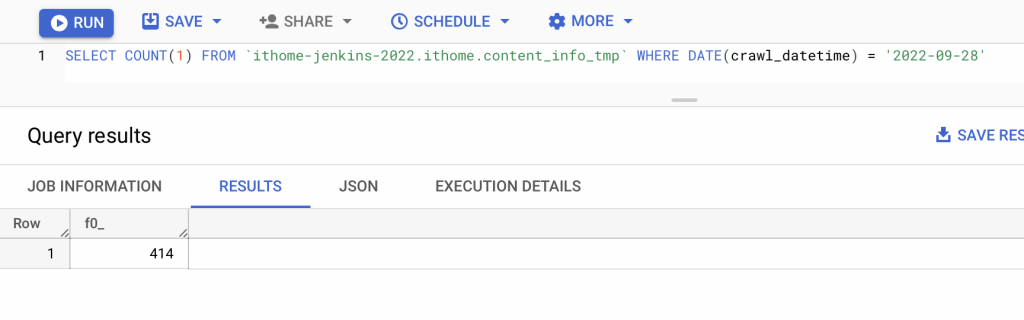
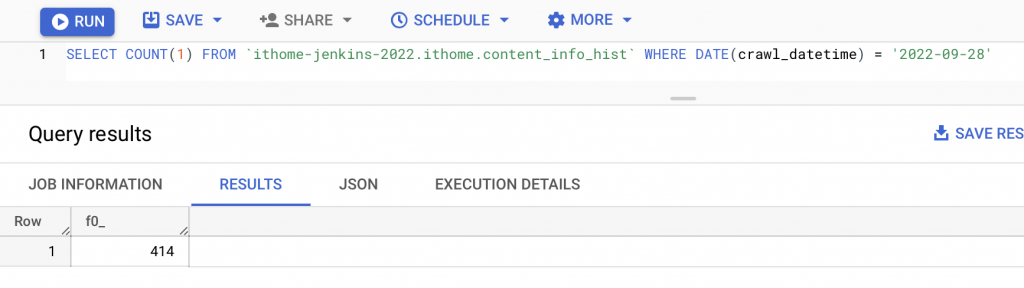
此確認邏輯亦可寫成一個 Jenkins 的 stage。(建議)
// overwrite_content_info_latest.sql
TRUNCATE TABLE `ithome-jenkins-2022.ithome.content_info_latest`;
INSERT INTO `ithome-jenkins-2022.ithome.content_info_latest`
SELECT
`_id`,
`crawl_datetime`,
`text`,
`user_id`,
`ironman_id`,
`title`,
`like`,
`comment`,
`view`,
`article_id`,
`article_url`,
`create_datetime`
FROM `ithome-jenkins-2022.ithome.content_info_hist`
WHERE DATE(crawl_datetime) = @execute_date
;
ithome.content_info_latest 全表更新為 @execute_date 的資料
BigQuery command
cat overwrite_content_info_latest.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${EXECUTE_DATE}"
Jenkinsfile
stage("Update to latest table"){
steps{
sh '''
cat sql/overwrite_content_info_latest.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${params.EXECUTE_DATE}"
'''
}
}
// overwrite_content_info_view_change.sql
TRUNCATE TABLE `ithome-jenkins-2022.ithome.content_info_view_change`;
INSERT INTO `ithome-jenkins-2022.ithome.content_info_view_change` (
`ironman_id`,
`article_id`,
`view`,
`crawl_datetime`,
`latest_datetime`
)
SELECT
`ironman_id`,
`article_id`,
`view`,
`crawl_datetime`,
CASE WHEN
DATE(crawl_datetime) = @execute_date THEN true ELSE false
END AS `latest_datetime`
FROM
`ithome-jenkins-2022.ithome.content_info_hist`
WHERE DATE(crawl_datetime) <= @execute_date
;
BigQuery command
cat overwrite_content_info_view_change.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${EXECUTE_DATE}"
Jenkinsfile
stage("Update to latest table"){
steps{
sh '''
cat sql/overwrite_content_info_view_change.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${params.EXECUTE_DATE}"
'''
}
}
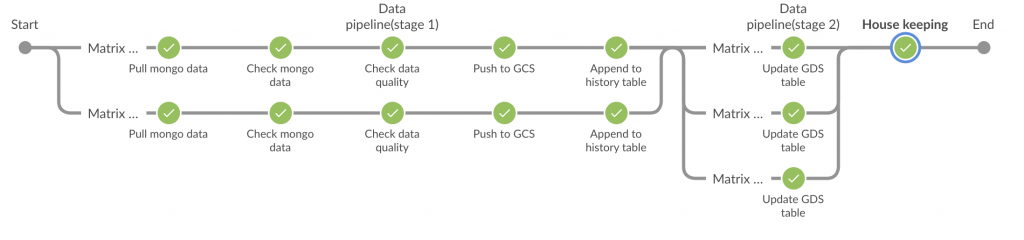
完整 Jenkinsfile
properties([parameters([
[$class: 'DateParameterDefinition',
name: 'EXECUTE_DATE',
dateFormat: 'yyyy-MM-dd',
defaultValue: 'LocalDate.now().plusHours(8)']
])])
pipeline {
agent{
label "gcp-agent-1"
}
environment {
MONGO_HOST = "mongodb://localhost:27017"
MONGO_DB = "ithome_ironman"
}
stages {
stage('Data pipeline(stage 1)') {
matrix {
axes {
axis {
name 'DATA'
values 'user_info', 'content_info'
}
}
stages {
stage("Pull mongo data"){
steps{
sh """
python3 mongo_client.py -c ${DATA} \
to-csv --csv-file-path output/${DATA}/${DATA}.csv
"""
}
}
stage("Check mongo data"){
steps{
sh '''
MONGO_DATA_COUNT=$(python3 mongo_client.py -c ${DATA} count-data --contain-header)
CSV_DATA_COUNT=$(cat output/${DATA}/${DATA}.csv|wc -l)
echo "Mongo data count: ${MONGO_DATA_COUNT}"
echo "CSV data count: ${CSV_DATA_COUNT}"
if [ $CSV_DATA_COUNT != $CSV_DATA_COUNT ]; then exit 1; fi
'''
}
}
stage("Check data quality"){
steps{
sh """
docker run -v ${WORKSPACE}/output/${DATA}/:/usr/src/github/ piperider run
"""
sh '''
sudo rm -rf ${WORKSPACE}/output/${DATA}/.piperider/outputs/latest
sudo ln -s ${WORKSPACE}/output/${DATA}/.piperider/outputs/$(ls ${WORKSPACE}/output/${DATA}/.piperider/outputs | grep ithome|tail -n1) ${WORKSPACE}/output/${DATA}/.piperider/outputs/latest
'''
sh "python3 get_piperider_result.py --data-source-name ${DATA} "
}
}
stage("Push to GCS"){
steps{
sh """
gcloud alpha storage cp output/${DATA}/${DATA}.csv gs://crawler_result/ithome/ironman2022
"""
}
}
stage("Append to history table"){
steps{
sh """
cat sql/update_${DATA}_hist.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${params.EXECUTE_DATE}"
"""
}
}
}
}
}
stage("Data pipeline(stage 2)") {
matrix {
axes {
axis {
name 'OUTPUT_TABLE'
values 'user_info_latest', 'content_info_latest', 'content_info_view_change'
}
}
stages {
stage("Update GDS table"){
steps{
sh """
cat sql/overwrite_${OUTPUT_TABLE}.sql | bq query \
--nouse_legacy_sql \
--parameter execute_date:DATE:"${params.EXECUTE_DATE}"
"""
}
}
}
}
}
stage("House keeping"){
steps{
sh "python3 mongo_client.py -c user_info housekeeping"
sh "python3 mongo_client.py -c content_info housekeeping"
}
}
}
post{
always{
archiveArtifacts artifacts: 'output/**', followSymlinks: false
}
}
}
Jenkinsfile 有以下幾點需要說明:
mongodb://localhost:27017
bq 或是 gcloud 的指令。sudo 權限的 (在某些情況下,這樣設定其實不太好)。stage - Check data quality 後來是用 Docker 去運行 piperider 的原因是 Jenkins Agent 預設只有 Python3.6 ,可是 PipeRider 最低需要 Python3.7 方能安裝,故最終使用官方的 Docker image 為基礎,去執行資料品質分析,但使用 Docker 同時衍生了一些路徑問題,可以在同一個 stage 的後半段看到,我重新做軟連接。花了幾天的時間帶著大家一步一步完成 CI/CD Pipeline 與 Data Pipeline,明天會介紹最終的 Google Data Studio 的分析報表。
https://towardsdatascience.com/15-essential-steps-to-build-reliable-data-pipelines-58847cb5d92f
https://learn.microsoft.com/zh-tw/power-bi/guidance/star-schema
https://stackoverflow.com/questions/53712774/jenkins-date-parameter-plugin-how-to-use-it-in-a-declarative-pipeline


 iThome鐵人賽
iThome鐵人賽